La desviación media
Valoración de la comunidad:
Última Actualización:
6 de Febrero de 2025 a las 17:07
La desviación media
Aprendizaje esperado: usa e interpreta las medidas de tendencia central (moda, media aritmética y mediana), el rango y la desviación media de un conjunto de datos, y decide cuál de ellas conviene más para el análisis de los datos en cuestión.
Énfasis: usar e interpretar el concepto de desviación media de un conjunto de datos como la diferencia de un valor a la media y su relación con la dispersión de los mismos.
¿Qué vamos a aprender?
En esta sesión, estudiarás las medidas de dispersión, específicamente, la desviación media y su utilidad. Para ello, resolverás diversos problemas de situaciones cotidianas que te permitan tomar decisiones importantes que estén basadas en datos.
¿Qué hacemos?
Inicia recuperando la definición de algunos conceptos útiles para el desarrollo de este tema. Anota las siguientes preguntas:
¿Cuáles son las medidas de tendencia central?
¿Qué es la moda?
¿Qué es la mediana?
¿Qué es la media?
¿Qué es el rango?
Tener una noción de estos conceptos es importante para describir y comprender de una manera concreta el comportamiento de un conjunto de datos. De ahí la importancia de tomar un breve tiempo para recuperar estos conceptos.
¿Qué son las medidas de tendencia central?
Las medidas de tendencia central más utilizadas son: la moda, la mediana y la media. Éstas son medidas estadísticas que sirven para describir de manera resumida y eficiente un conjunto de datos.
¿Qué es la moda?
Una manera estadísticamente apropiada de definir esta medida o parámetro es como el dato que ocurre con mayor frecuencia, es decir, el que más se repite, y se simboliza con las letras “Mo”. También es usual representarla de la siguiente manera:
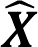
Debes tener en cuenta que un conjunto de datos puede no tener moda, tener una moda (unimodal), tener dos modas (bimodal) o más de dos modas (multimodal).
¿Qué es la mediana?
La mediana es el valor que ocupa el lugar central de todos los datos, siempre y cuando el número de datos sea impar. Es muy importante tener presente que los datos deben ser colocados de forma ordenada, además, cuando el conjunto de datos es un número par, la mediana será el promedio de los dos datos centrales. El símbolo de la mediana es “Me”. También es común representarla de la siguiente manera:
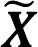
¿Qué es la media?
La media o media aritmética es el promedio de un conjunto de datos. Si los datos provienen de una muestra, se simboliza con una equis testada.
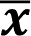
Si los datos provienen de una población, su símbolo será la letra griega “mu”.
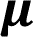
¿Qué es el rango?
A diferencia de las otras medidas, el rango es una medida de dispersión. Se define como la diferencia entre el valor máximo y el valor mínimo de un conjunto de datos y puede simbolizarse con la letra “R”. Es útil para dar una idea de la dispersión de los datos, mientras más dispersos están los datos, mayor es el rango.
Antes de continuar en el tema, reflexiona en las medidas de dispersión, en este caso del rango. Para ello, analiza la siguiente situación.
Situación 1
Dos equipos de alumnos realizaron la medición de la longitud de un mismo objeto en el laboratorio. Los resultados en milímetros fueron los siguientes:
- Equipo A: 8, 9, 10, 10, 10, 11 y 12.
- Equipo B: 5, 7, 10, 10, 10, 13 y 15.
¿Qué equipo realizó una mejor medición de ese objeto?
En este caso, la moda para los datos de los dos equipos es 10. La mediana es una medida que también coincide, es decir, 10. Por otro lado, la media también es la misma, 10.

Entonces, ¿cómo se puede determinar qué equipo hizo una mejor medición?
Si se considera el rango, los datos del equipo A tienen un rango de 4 milímetros y los del equipo B, de 10 milímetros.

Como puedes observar, las medidas obtenidas por el equipo A tienen menor dispersión o variabilidad, por lo que puede considerarse que este equipo realizó una mejor medición del objeto en cuestión.
Entonces, en esta situación, el rango fue el parámetro que ayudó a tomar la decisión cuando las medidas de tendencia central no ayudaron lo suficiente. Pero, además del rango ¿existen otras maneras de medir la separación de los datos de un conjunto?
Analiza la siguiente información para dar respuesta a la cuestión anterior.
¿Qué son las medidas de dispersión?
Las medidas de dispersión miden la separación o variabilidad de un conjunto de datos. Existen diversas medidas de dispersión, por lo que, en esta sesión, te centrarás en la desviación media.
Ahora, resuelve la siguiente situación para aprender a calcular la desviación media.
Situación 2
Se tienen dos conjuntos de datos, determina para cada uno la moda, mediana, media y rango; además, argumenta en cuál de los dos hay mayor dispersión.
- El conjunto “A” contiene los números: 10, 5, 8, 15, 2.
- El conjunto “B” contiene los números: 8, 9, 8, 14, 1.
Inicia con el conjunto “A”.
¿Cuál es la moda del conjunto A? El conjunto A no tiene moda, porque ningún dato se repite.
¿Cuál es la mediana del conjunto A? Para determinarla, primero se deben reacomodar los datos de forma ordenada, es decir, de mayor a menor o viceversa. El orden de los datos del conjunto A es:
2, 5, 8, 10, 15
Una vez ordenados, se puede observar al número 8 como valor central, entonces, el 8 es la mediana del conjunto A.
¿Cuál es la media del conjunto A? Toma un momento para hacer los cálculos. Ten presente que se calcula sumando todos los valores de los datos para después dividir el resultado entre la cantidad de datos. En este caso, la suma de:
2 + 5 + 8 + 10 + 15 = 40
Como se cuenta con 5 datos, entonces se divide 40 entre 5, el resultado es igual a 8. Es decir, la media de datos del conjunto A, es 8.
Para calcular el rango, solamente debes realizar la diferencia entre el valor máximo y el valor mínimo. Esto es:
15 - 2 = 13
El rango del conjunto de datos A, es 13. Por lo tanto, las medidas del conjunto “A”, quedan de la siguiente manera:
Conjunto A
Moda = no tiene
Mediana = 8
Media = 8
Rango = 13
Ahora, aplica el mismo procedimiento para el conjunto de datos “B”.
La moda del conjunto de datos “B” es 8, porque es el dato que aparece dos veces. La frecuencia de este dato es dos y la de los demás datos es solamente 1.
Al ordenar los datos de menor a mayor, es visible que la mediana del conjunto de datos “B” es 8.
Para calcular la media, se deben sumar los datos, esto es:
1 + 8 + 8 + 9 + 14 = 40
Como se tienen 5 datos, 40 se divide entre 5 y el cociente es 8, es decir, la media del conjunto de datos “B” es 8.
Aún falta determinar el valor del rango, para ello, se resuelve la resta:
14 – 1 = 13
Esto porque 14 representa el dato con mayor valor y 1 es el dato con menor valor. El resultado es 13, es decir, el valor del rango de conjunto de datos “B” es 13.
Por lo tanto, las medidas del conjunto “B”, quedan de la siguiente manera:
Conjunto B
Moda = 8
Mediana = 8
Media = 8
Rango = 13
De los parámetros que se determinaron, ¿cuál es el más apropiado para definir la dispersión de los datos en cada conjunto?
En este caso es el rango, pues es la única medida nos otorga información sobre la dispersión de los datos.
Ahora, reflexiona: ¿cuál dirías que es el conjunto de datos con mayor dispersión? Toma un momento para pensarlo.
Como seguramente ya identificaste, en ambos conjuntos de datos el rango es 13, esto quiere decir que, si se usa el rango, ambos conjuntos están igual de dispersos.
Contesta las siguientes preguntas y argumenta tu respuesta:
¿Qué significa esto?
¿Los dos conjuntos están igual de dispersos?
¿El rango considera todos los datos para evaluar la dispersión?
Como sabes, el rango es una medida de dispersión que únicamente considera dos valores para determinar la dispersión en un conjunto de datos. Sin embargo, ignora el resto de los datos.
Para tener una descripción más apegada a la realidad sobre la dispersión de un conjunto de datos, es necesario considerar la totalidad de estos.
Como se mencionó anteriormente, las medidas de dispersión son útiles para identificar que tan separados o concentrados están los datos del centro. En ese sentido, ¿cuál supones que es la medida de tendencia central más práctica para representar los datos de un conjunto numérico?
La media es el parámetro más práctico que otorga un panorama general de los datos. Entonces, para medir que tan dispersos están los datos, se puede calcular la distancia de cada dato a la media.
Comienza con el conjunto de datos “A”. La media es 8, por lo tanto, se debe de realizar la diferencia de cada dato con la media. Para hacer el registro de las operaciones, apóyate en una tabla.
El primer dato es 2, por lo tanto, se resta 8 menos 2 y es igual a 6. Se repite el procedimiento con cada uno de los datos. El segundo dato es 5, así que se resta 8 menos 5 y es igual a 3, se registra en la tabla el resultado para continuar con la siguiente diferencia. Es decir, 8 menos 8 es igual a cero; 10 menos 8 es igual a 2 y, por último, 15 menos 8 es igual a 7. Con estas diferencias, ya tienes la distancia de cada dato del conjunto “A” respecto a la media. Observa cómo queda la tabla:

Lo siguiente es hacer lo mismo para el conjunto de datos “B”. La media de este conjunto también es 8, así que se debe restar cada dato de este conjunto con la media.
El primer dato es 1, así que se resta 8 menos 1 y es igual a 7. El segundo dato es 8, al restarlo a la media, el resultado es cero. El tercer dato, también es 8, por lo que la diferencia con la media es cero. El siguiente dato es 9, menos la media es igual a 1. Por último, 14 menos 8 es igual a 6 y con este resultado se ha completado el registro de datos de la tabla del conjunto de datos “B”. Observa cómo queda:

Cada uno de estos resultados significa la distancia a la que está cada dato de la media, por ejemplo, en la tabla del conjunto de datos “A”:

El 6 significa que el 2 está a una distancia de 6 unidades de la media; el 3 significa que el 5 está a una distancia de 3 unidades de la media y así sucesivamente.
El mismo significado tienen los resultados de la tabla de datos del conjunto “B”, por ejemplo:

Cada número cero, significa que el 8 y la media, están en la misma posición, por lo que no hay una distancia entre ellos.
Entonces:
¿Son suficientes estos resultados para saber cuál conjunto de datos está más disperso?, ¿por qué?
¿En cuál conjunto de datos hay distancias más grandes?
Escribe una conclusión al respecto.
Estos resultados muestran un panorama de la dispersión de cada uno de los datos respecto a la media.
Seguramente ya identificaste que el conjunto de datos “A” tiene una suma de estas distancias mayor que la suma de las distancias del conjunto de datos “B”, esto es visible si se observan los resultados de las diferencias. ¿Se te ocurre una forma de saber la “dispersión total” en cada conjunto de datos? Piénsalo un momento.
Si se calcula el promedio de las distancias a la media en cada conjunto de datos, podrás tener una única medida que permita comparar ambos conjuntos de datos y determinar así, cuál de ellos presenta mayor dispersión.
Ten presente que el promedio de cualquier conjunto de datos se calcula sumando los valores de los datos para después dividir el resultado entre el número total de datos.
Los valores de las distancias a la media del conjunto de datos “A” son: 6, 3, 0, 2 y 7; la suma de esos valores es igual a 18. Ahora, divide 18 entre 5 y el cociente es 3.6.

El procedimiento se repite para las distancias a la media del conjunto de datos “B”, estas son: 7, 0, 0, 1, 6; la suma de esos valores es igual a 14. Después, 14 se divide entre 5 y el cociente es 2.8.

Con estos datos, es posible definir cuál conjunto de datos tiene mayor dispersión. La dispersión para el conjunto de datos “A” es de 3.6, mientras que la dispersión para el conjunto de datos “B” es de 2.8. En otras palabras, el conjunto de datos “A” tiene mayor dispersión.
El procedimiento que acabas de realizar para calcular el valor del promedio, de las distancias de cada uno de los datos a su media, se le conoce como desviación media, y puede ser simbolizado con las letras “DM”, además, es considerada una mejor medida que el rango para describir la dispersión en un conjunto de datos, pues a diferencia del rango, la desviación media considera la totalidad de los datos.
Hasta este momento, has aprendido a calcular la desviación media y su utilidad como medida de dispersión, pero seguramente te estarás preguntando, ¿cuál es su utilidad en la cotidianidad?
Descúbrelo resolviendo la siguiente situación.
Situación 3
Tres alumnos participaron en una competencia para probar sus conocimientos en 10 materias diferentes, para ello, se les aplicó una prueba con 10 preguntas. El propósito es seleccionar al alumno para representar a la escuela en una competencia estatal. Los resultados de cada alumno se muestran en la siguiente tabla.
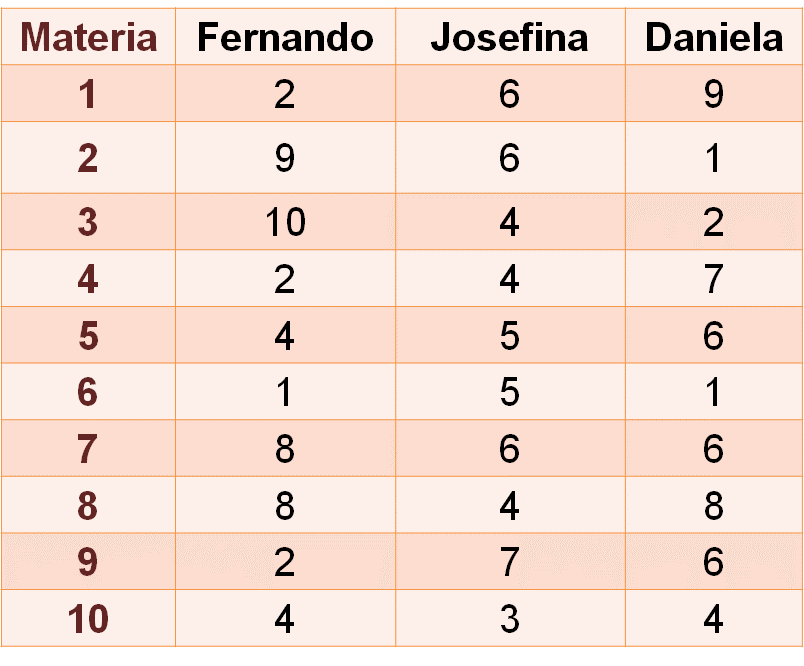
En la primera columna aparece la materia, en la segunda columna se muestran las puntuaciones obtenidas de Fernando, en la tercera columna las puntuaciones obtenidas por Josefina y en la cuarta columna el puntaje obtenido de Daniela.
Con los datos que aparecen en la tabla, determina quién es el alumno que debiera representar a la escuela a nivel estatal.
¿Qué medidas utilizarás para tomar esa decisión? Toma un instante para pensarlo y resuelve la situación.
Una manera práctica de tomar la decisión sobre la selección del alumno es determinar la media aritmética de las calificaciones de cada alumno, ya que es una medida que se puede calcular fácilmente y siempre se encuentra definida para datos numéricos. Si se calcula la media de los datos, es posible calcular también la desviación media.
Fernando:
Siguiendo el orden de la tabla, el primer alumno es Fernando y sus calificaciones son: 2, 9, 10, 2, 4, 1, 8, 8, 2, 4, que sumadas son igual a 50. Se divide 50 entre 10 para calcular el promedio y el cociente es 5, esto quiere decir que el puntaje promedio de Fernando es de 5.
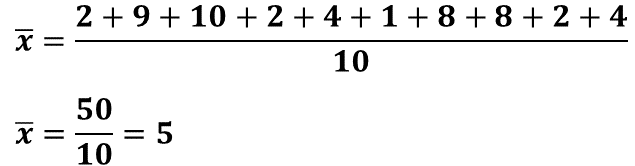
Para calcular la desviación media de los puntajes obtenidos por Fernando, primero se deben calcular las distancias de cada puntaje respecto a la media, esto es, 5 menos 2; 9 menos 5; 10 menos 5; 5 menos 2; 5 menos 4; 5 menos 1; 8 menos 5; otra vez 8 menos 5; 5 menos 2 y finalmente, 5 menos 4. Los resultados se suman y el total es igual a 30. Después, 30 se divide entre 10 y el cociente es 3. Ese valor, corresponde a la desviación media.
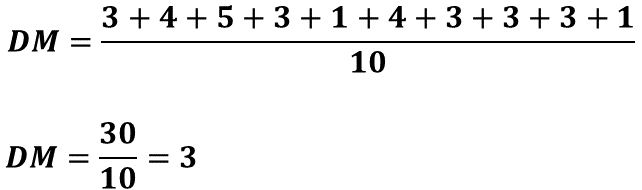
En otras palabras, Fernando responde en promedio 5 preguntas correctamente y con una dispersión o variabilidad de 3 aciertos. Es decir, su desempeño está, en promedio, entre 2 y 8 preguntas respondidas correctamente.
Josefina:
Para realizar el análisis del desempeño de Josefina en la prueba, se realizan los mismos procedimientos, primero se calcula la media aritmética de sus puntajes. Después, se calculan las distancias de cada uno de sus puntajes respecto a la media y, por último, se calcula el promedio de las distancias respecto a la media.
Los puntajes de Josefina son: 6, 6, 4, 4, 5, 5, 6, 4, 7, 3; que al sumarlos su total es de 50. Luego, 50 se divide entre 10 y el cociente es 5. Significa que Josefina responde acertadamente 5 preguntas en promedio.
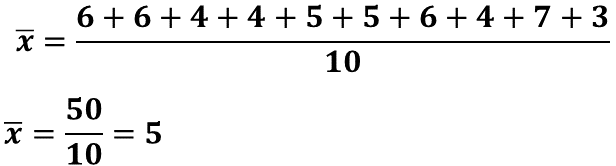
Ahora, calcula la desviación media. Para ello, primero se calculan las distancias de cada punto respecto a la media y se hace, como bien sabes, calculando la diferencia entre cada puntaje y 5 que representa la media, las distancias calculadas son: 1, 1, 1, 1, 0, 0, 1, 1, 2, 2. Se suman las distancias y el resultado se divide entre 10, de tal manera que se obtiene la división de 10 entre 10, se resuelve y el cociente es 1.
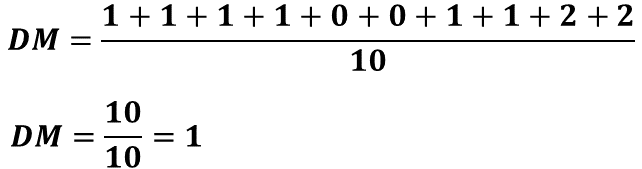
Esto significa que, en promedio, Josefina responde correctamente 5 preguntas con una dispersión o variabilidad de 1 pregunta. Es decir, su desempeño está, en promedio, entre 4 y 6 preguntas respondidas correctamente.
Daniela:
Para realizar el análisis del desempeño de Daniela en la prueba, primero se calcula el promedio de sus calificaciones. Después, se calculan las distancias de cada puntaje respecto a la media y para finalizar, se calcula la desviación media, que permitirá describir con mayor precisión su desempeño.
Los puntajes obtenidos por Daniela son: 9, 1, 2, 7, 6, 1, 6, 8, 6, 4, que sumadas dan un total de 50. Entonces, 50 se divide entre 10 y el cociente es 5, que representa la media del puntaje obtenido por Daniela.
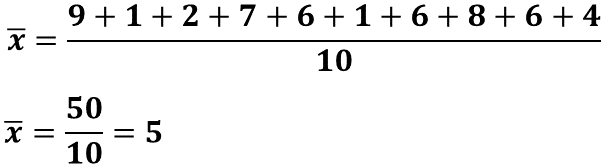
Después se calculan las distancias de cada puntaje respecto a la media. Éstas son: 4, 4, 3, 2, 1, 4, 1, 3, 1, 1. Estas distancias se suman y dan un total de 24, el total se divide entre 10 y el cociente es igual a 2.4, que representa la variabilidad del desempeño de Daniela en la prueba.
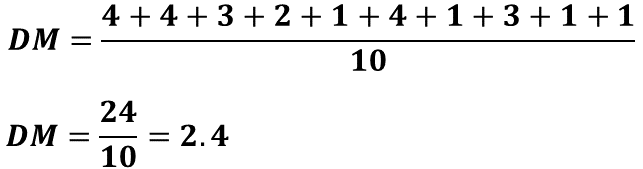
En otras palabras, Daniela responde correctamente 5 preguntas, con una dispersión o variabilidad de 2.4 aciertos. Por esto se puede decir que su desempeño está, en promedio, entre 2.6 y 7.4 preguntas respondidas correctamente.
Es momento de responder la pregunta que plantea la situación: ¿quién es el alumno que debería representar a la escuela en la competición estatal?
La siguiente tabla muestra el resumen de los datos calculados sobre el desempeño de Fernando, Josefina y Daniela. Con el análisis previamente realizado y con los datos calculados, se puede seleccionar al alumno que debe representar a la escuela.

Escribe tu elección en tu cuaderno, argumenta tu respuesta y compara a la distancia tus argumentos con los de tus compañeras y compañeros.
En la tabla se puede observar que tanto Fernando como Josefina y Daniela, tienen el mismo desempeño respecto al promedio de aciertos, por lo que, con la media aritmética como único criterio no se puede elegir al alumno que debería representar a la escuela. Por ello, la necesidad de calcular otro parámetro que ayude a describir mejor el desempeño de cada uno de ellos.
En este caso, la desviación media resulta más útil, ya que muestra la distancia en la que se pueden desempeñar respecto a la media, es decir, da información sobre la cantidad de respuestas correctas que cada uno puede esperar obtener tanto por abajo como por encima de la media.
Considerando lo anterior, la candidata que debe representar a la escuela en la competición estatal es Josefina, pues ella presenta menor dispersión o variabilidad en su desempeño, que es deseable en este caso, porque se espera que sus resultados en las pruebas de selección sean parecidos a los que obtenga en la siguiente etapa del concurso, donde el alumno ganador será quien obtenga un mayor número de respuestas correctas.
Como seguramente ya identificaste, calcular la desviación media resulta útil para ayudar a tomar decisiones importantes que estén basadas en datos, como la de la situación anterior. Sin embargo, es importante mencionar que existen otros parámetros para describir mejor los conjuntos de datos, y con base en ello, procurar tomar decisiones más juiciosas. Inclusive, en algunas ocasiones las decisiones deben tomarse con criterios de otras áreas de las matemáticas o, con criterios que no son matemáticos. En tus estudios posteriores aprenderás más sobre esto.
Has finalizado esta sesión. Recuerda que este es un material de apoyo y para complementar lo estudiado, puedes consultar otras fuentes, como tu libro de texto de matemáticas de segundo grado.
El reto de hoy:
Resuelve algunos problemas y situaciones sobre las medidas de dispersión, específicamente, la desviación media. Para ello, consulta tu libro de texto de Matemáticas de segundo grado.
¡Buen trabajo!
Gracias por tu esfuerzo.
Para saber más:
Lecturas


Login to join the discussion